
3 - Couche de données brutes dans BigQuery
Nous allons manipuler BigQuery au travers de la console cloud.
Nous allons créer un dataset, une table externe et une table native pour contenir nos données brutes.
Dataset
Ouvrez le service BigQuery dans la console cloud : https://console.cloud.google.com/bigquery?project=workshop-data-platform
Créons le dataset raw dans notre projet.
✏ Cliquez sur les trois points à droite du nom du projet, puis sur "Créer un ensemble de donnée"
✏ Renseignez le Dataset ID ("[PREFIX]_ds_raw") et sélectionnez la région ("europe-west1")
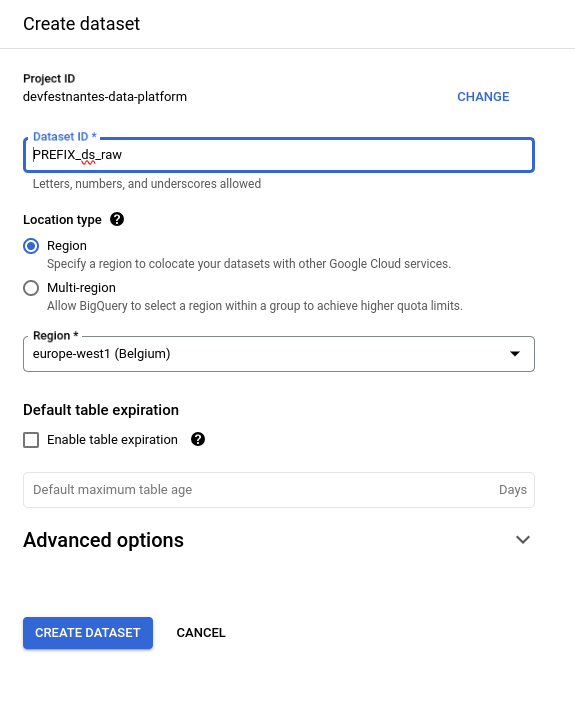
✏ Cliquez sur le bouton CREATE DATASET pour finaliser la création
|
Vous pouvez aussi utiliser la commande suivante dans cloud shell pour créer le dataset: |
Table des départements
Pour manipuler le tableau des départements, nous allons utiliser une table externe : c’est un modèle de table BigQuery où la donnée est lue directement depuis un fichier.
✏ Cliquez sur les trois points à droite du nom du dataset [PREFIX]_ds_raw puis sur "Create table"
✏ Remplissez le formulaire
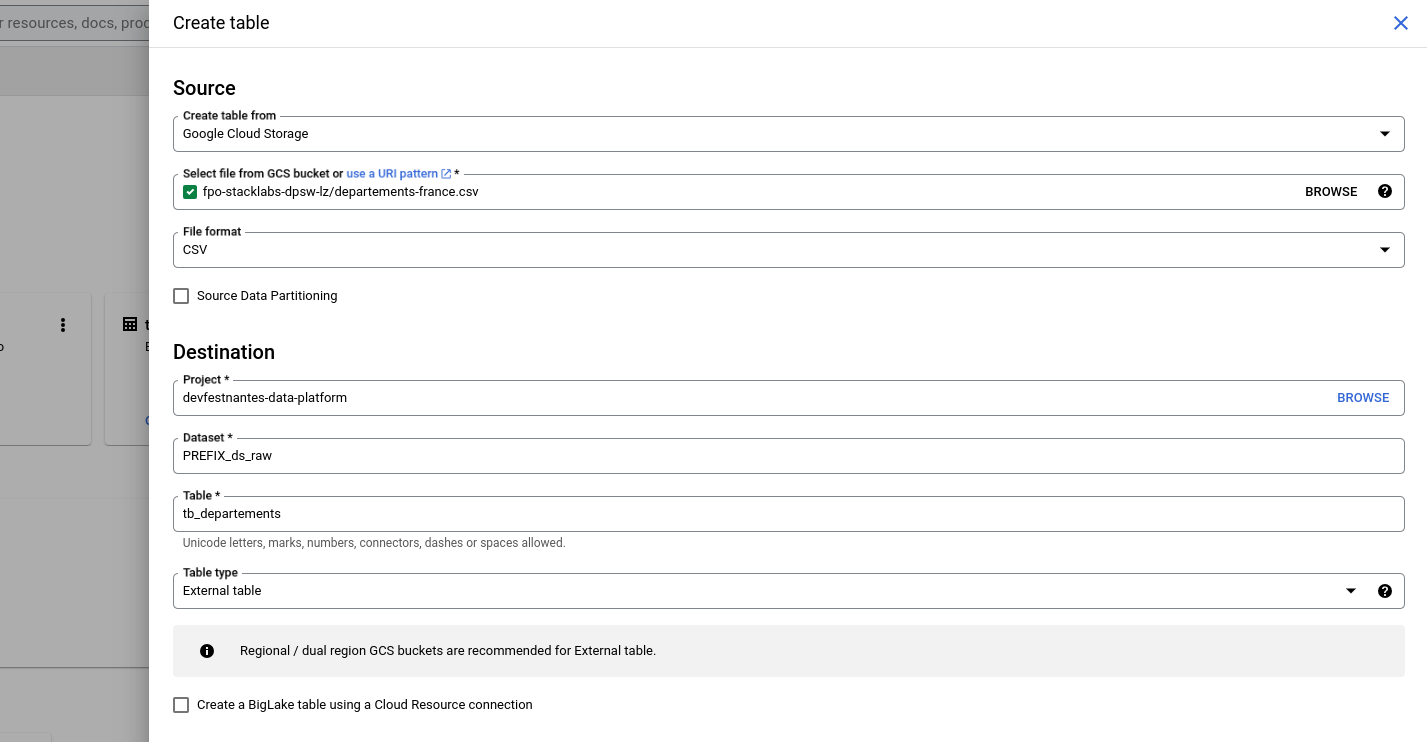
| Attention à bien renseigner "External table" dans le champs "Table type" |
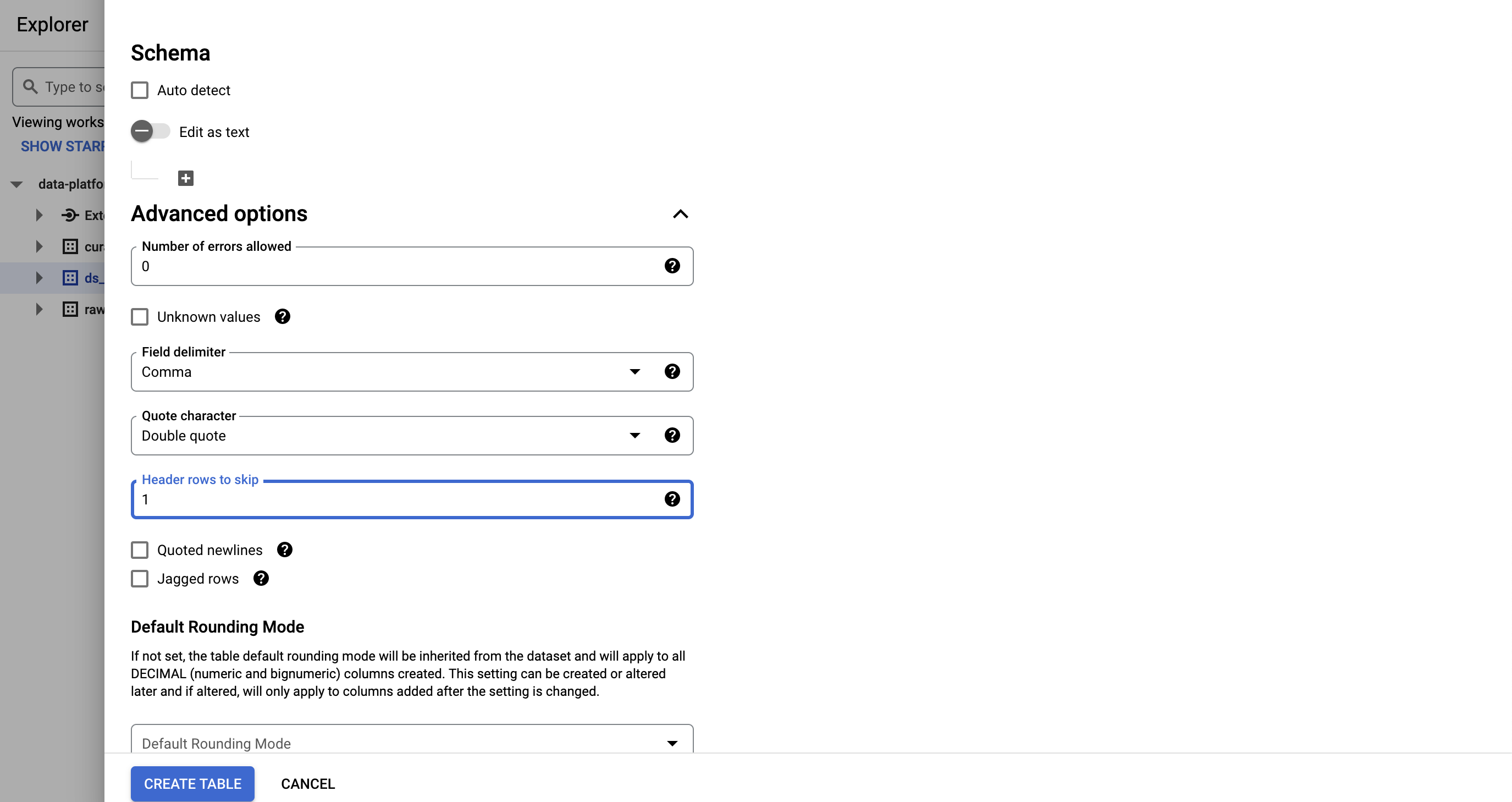
La première ligne du fichier contient les noms des colonnes, c’est pourquoi il faut indiquer 1 header row to skip
|
✏ Cliquez sur CREATE TABLE
La table est maintenant créée, mais comme son schéma n’a pas été spécifié, il est impossible de la requeter.
Pour remédier à cela, sélectionnez la nouvelle table puis cliquez sur EDIT SCHEMA
✏ Activez le bouton Edit as text et copiez le schéma suivant:
[
{
"name": "code_departement",
"type": "STRING"
},
{
"name": "nom_departement",
"type": "STRING"
},
{
"name": "code_region",
"type": "STRING"
},
{
"name": "nom_region",
"type": "STRING"
}
]✏ Cliquez sur SAVE.
|
Vous pouvez aussi utiliser la commande suivante dans cloud shell pour créer la table: |
Rendez vous sur l’onglet QUERY pour effectuer des requêtes sur la table externe
SELECT * FROM `<PROJET>.[PREFIX]_ds_raw.tb_departements`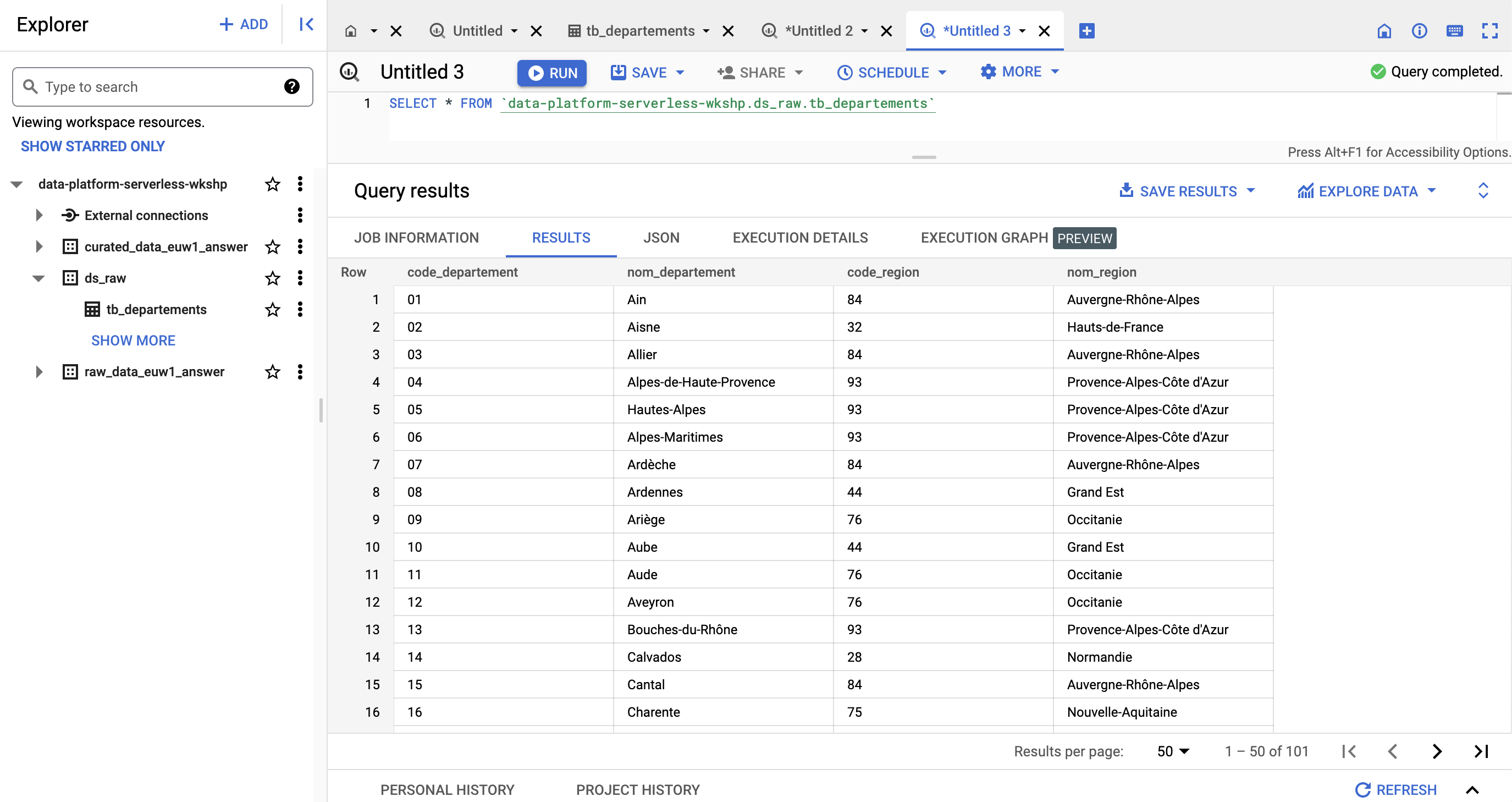
Table des naissances
Pour les naissances, nous allons construire une table native, dont le stockage optimisé permet les requêtes les plus efficaces
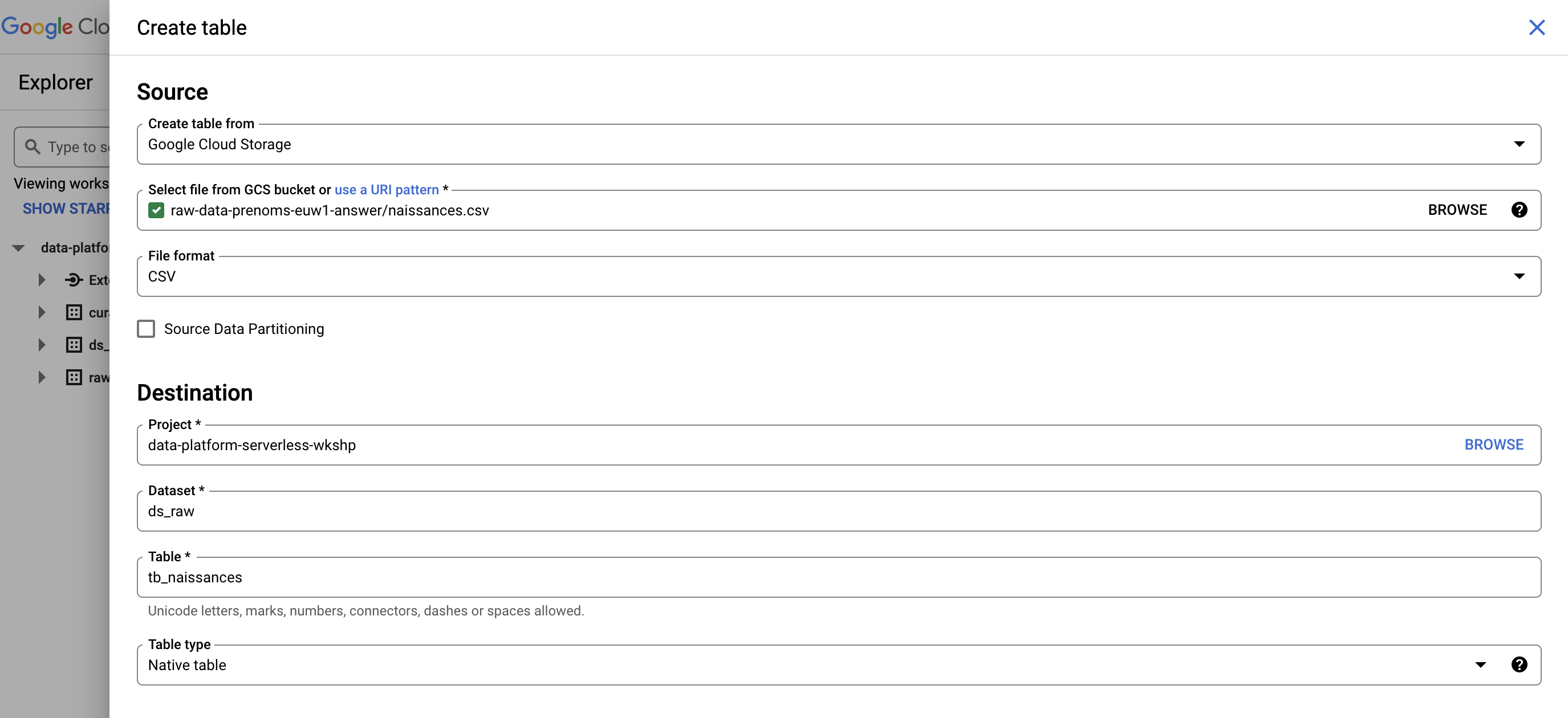
✏ Cliquez sur les trois points à droite du nom du dataset [PREFIX]_ds_raw puis sur "Create table"
✏ Remplissez le formulaire comme précédemment mais cette fois indiquez:
-
Table type" : "Native table"
-
File:
dpsw-raw-data/naissance-part-0.csv -
Schema : il faut déclarer le schéma à la création de la table
-
Custom delimiter: ";"
En effet ce fichier CSV est délimité par des point-virgules, ce qui n’est pas le délimiteur par défaut.
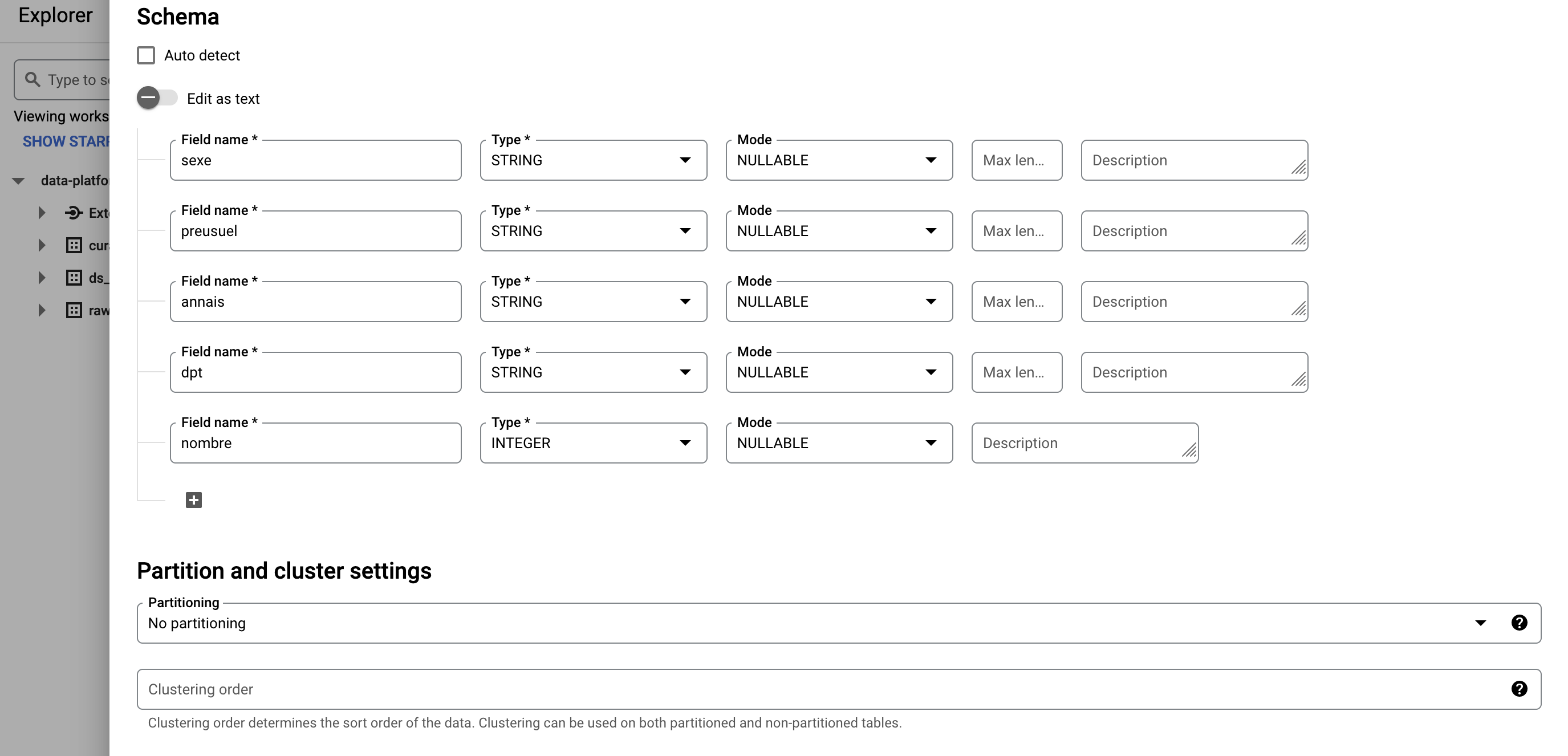
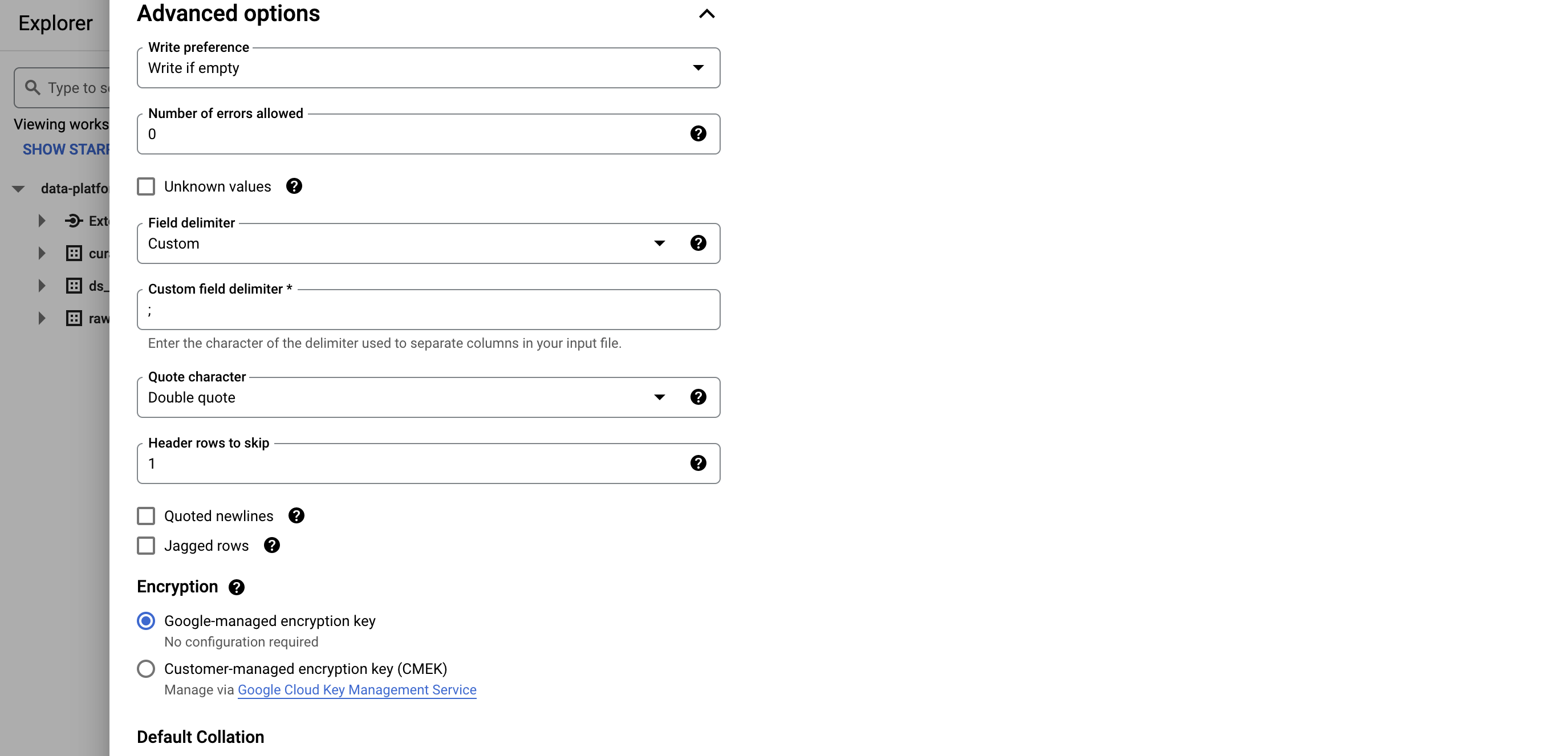
Vous pouvez remplir la partie schéma facilement en activant le bouton Edit as text et en y copiant le schéma suivant:
|
[
{"name":"sexe","type":"STRING","mode":"NULLABLE"},
{"name":"prenom","type":"STRING","mode":"NULLABLE"},
{"name":"annee_naissance","type":"STRING","mode":"NULLABLE"},
{"name":"code_departement","type":"STRING","mode":"NULLABLE"},
{"name":"nombre","type":"STRING","mode":"NULLABLE"}
]✏ Cliquez sur CREATE TABLE
Le job de création et de chargement prend environ 30 secondes. Une fois la création terminée, cliquez sur le nom de la table puis sur l’onglet PREVIEW pour avoir un aperçu des données chargées
| L’aperçu n’est disponible que sur les tables natives. Pour voir le contenu d’une table externe, il est nécessaire de faire une requête. |
Nous venons de voir deux manières de charger les données de la couche Raw dans BigQuery. Cependant, cela a entraîné un grand nombre d’opération manuelles. Pour améliorer l’opérabilité de notre chargement de données, nous allons devoir l’automatiser.