
4 - Cloud function
Écrivons une cloud function pour automatiser le chargement de la table des naissances à chaque fois qu’un fichier .csv dont le nom commence par "naissance" est déposé dans notre bucket.
Dans ce tutoriel nous utilisons le langage Python, mais d’autres langages sont supportés : Nodejs, Go, Java, .Net, Ruby, PHP. Si vous préférez expérimenter dans un de ces langages, c’est tout à fait possible, référez-vous pour celà à la documentation
|
Écriture de la fonction
Accédons au service des Cloud Functions au travers de la console GCP
✏ Cliquez sur le bouton CREATE FUNCTION au centre de l’écran
✏ Remplissez la première page du formulaire:
-
laissez l’environnement "1st gen"
-
donnez le nom suivant à la fonction: "<PREFIX>-load-naissances"
-
choisissez la région "europe-west1"
-
nous souhaitons que la fonction soit appelée à chaque fois qu’un fichier est déposé dans le bucket, donc choisissez le trigger "Cloud storage" avec le configuration suivante (pensez à sélectionner votre bucket)
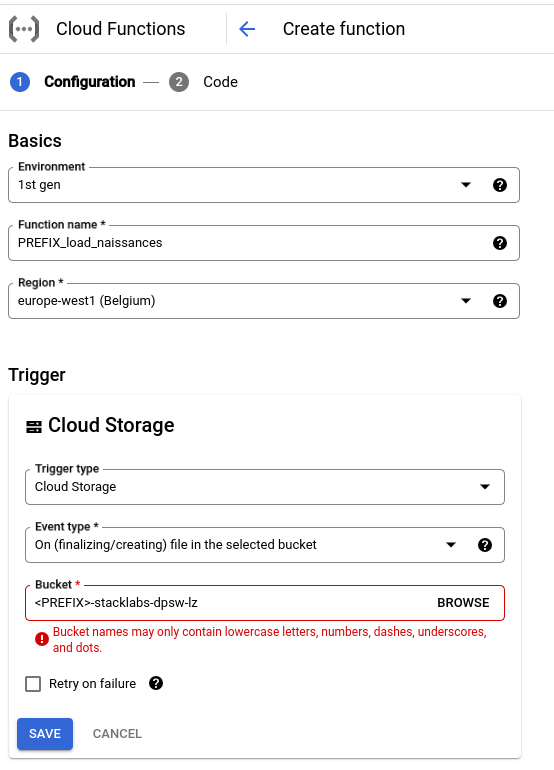
✏ Modifiez les paramètres d’execution de la fonction:
Modifiez le compte de service d’execution afin d’utiliser le service account dédié à la fonction sa-workshop@{PROJECT}.iam.gserviceaccount.com
|
✏ Cliquez sur le bouton NEXT pour accéder à la suite de la définition de la fonction
✏ Choisissez le runtime Python 3.10 dans la liste déroulante (ou autre runtime si vous préférez utiliser un autre langage pour cet exercice)
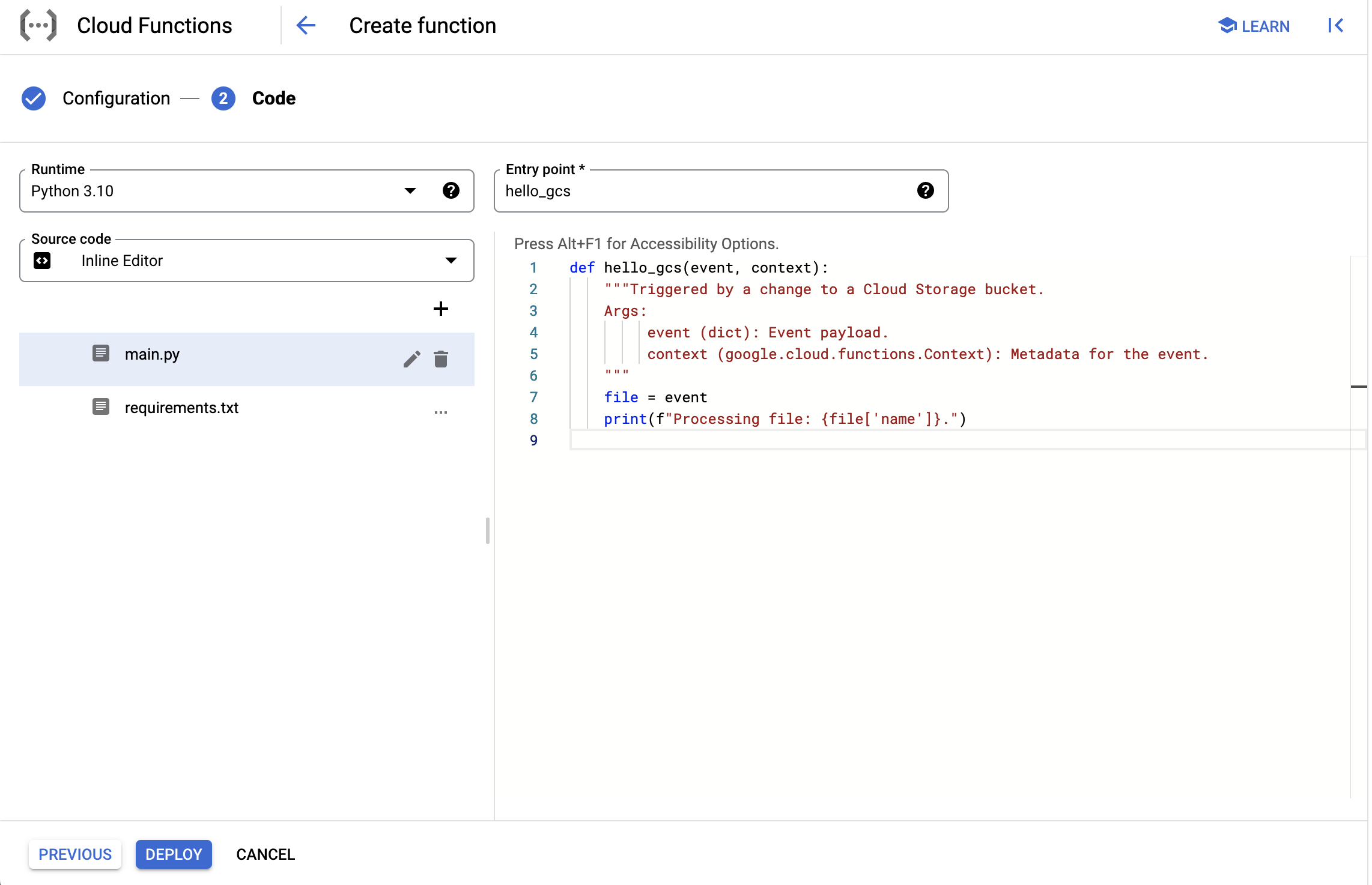
Ici il s’agit de saisir le code source de la fonction.
| Pensez à changer l’entry point de la fonction. L’entry point de la fonction est le nom de la fonction python qui sert de point d’entrée lors de l’appel de la cloud function. |
Voyez le fichier requirements.txt sur la gauche qui vous permet de déclarer des librairies dont votre fonction a besoin
✏ Ajoutez la librairie cliente Python pour BigQuery afin de pouvoir facilement invoquer les services de BigQuery
google-cloud-bigquery==3.7.0✏ Écrivez le code de la fonction de chargement
|
Vous pouvez suivre la documentation Google Cloud pour charger le contenu d’un fichier csv dans une table. Vous pouvez aussi utiliser et compléter le code Python suivant afin de réaliser l’exercice.
from google.cloud import bigquery
PROJECT = "workshop-data-platform"
PREFIX = "YOUR-PREFIX-HERE"
RAW_NAISSANCES_TABLE = f"{PROJECT}.{PREFIX}_ds_raw.tb_naissances"
LOCATION = "europe-west1"
FILE_NAISSANCES_PREFIX = "naissance"
def load_raw_file_incremental(event, context):
"""Triggered by a change to a Cloud Storage bucket.
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
"""
print(f"Processing file: {event['name']}.")
filename = event["name"]
# if payload file match pattern
# Load file
print(f"Unrecognized file {filename}, nothing to do")
def load_naissances(source: str):
"""Load naissances raw file from cloud storage."""
bq_client = bigquery.Client() # instantiate a bigquery client
# write here the load job
# The csv schema is provided below for convenience
# schema=[
# bigquery.SchemaField("sexe", "STRING"),
# bigquery.SchemaField("prenom", "STRING"),
# bigquery.SchemaField("annee_naissance", "STRING"),
# bigquery.SchemaField("code_departement", "STRING"),
# bigquery.SchemaField("nombre", "STRING")
# ]
load_job.result() # Waits for the job to complete.
print("Naissances loaded")⚠️ SPOILER ALERT: Solution d’implémentation en Python
from google.cloud import bigquery
PROJECT = "workshop-data-platform"
PREFIX = "YOUR-PREFIX-HERE"
RAW_NAISSANCES_TABLE = f"{PROJECT}.{PREFIX}_ds_raw.tb_naissances"
LOCATION = "europe-west1"
FILE_NAISSANCES_PREFIX = "naissance"
def load_raw_file_incremental(event, context):
"""Triggered by a change to a Cloud Storage bucket.
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
"""
print(f"Processing file: {event['name']}.")
filename = event["name"]
if not filename.endswith(".csv"):
print(f"Skip received file {filename} as it is not a CSV")
return
if filename.startswith(FILE_NAISSANCES_PREFIX):
load_naissances(f"gs://{event['bucket']}/{event['name']}")
return
print(f"Unrecognized file {filename}, nothing to do")
def load_naissances(source: str):
"""Load naissances raw file from cloud storage."""
bq_client = bigquery.Client()
load_job = bq_client.load_table_from_uri(
source_uris=source,
destination=RAW_NAISSANCES_TABLE,
location=LOCATION,
job_config=bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("sexe", "STRING"),
bigquery.SchemaField("prenom", "STRING"),
bigquery.SchemaField("annee_naissance", "STRING"),
bigquery.SchemaField("code_departement", "STRING"),
bigquery.SchemaField("nombre", "STRING")
],
source_format=bigquery.SourceFormat.CSV,
field_delimiter=";",
skip_leading_rows=1
),
)
load_job.result() # Waits for the job to complete.
print("Naissances loaded")
Vous pouvez aussi dupliquer la fonction load_naissances par un clic droit → copier la fonction.
|
✏ Cliquez sur DEPLOY
Le déploiement prend environ 5 minutes
Test de la fonction
✏ Supprimez la table tb_naissances préalablement créée dans votre dataset (Clic sur les 3 points à droite du nom de la table dans BigQuery puis Delete)
✏ Rechargez tous les fichiers naissances-part-[0-9]+.csv dans le bucket de dépôt en choisissant l’option Overwrite dans la boîte de dialogue
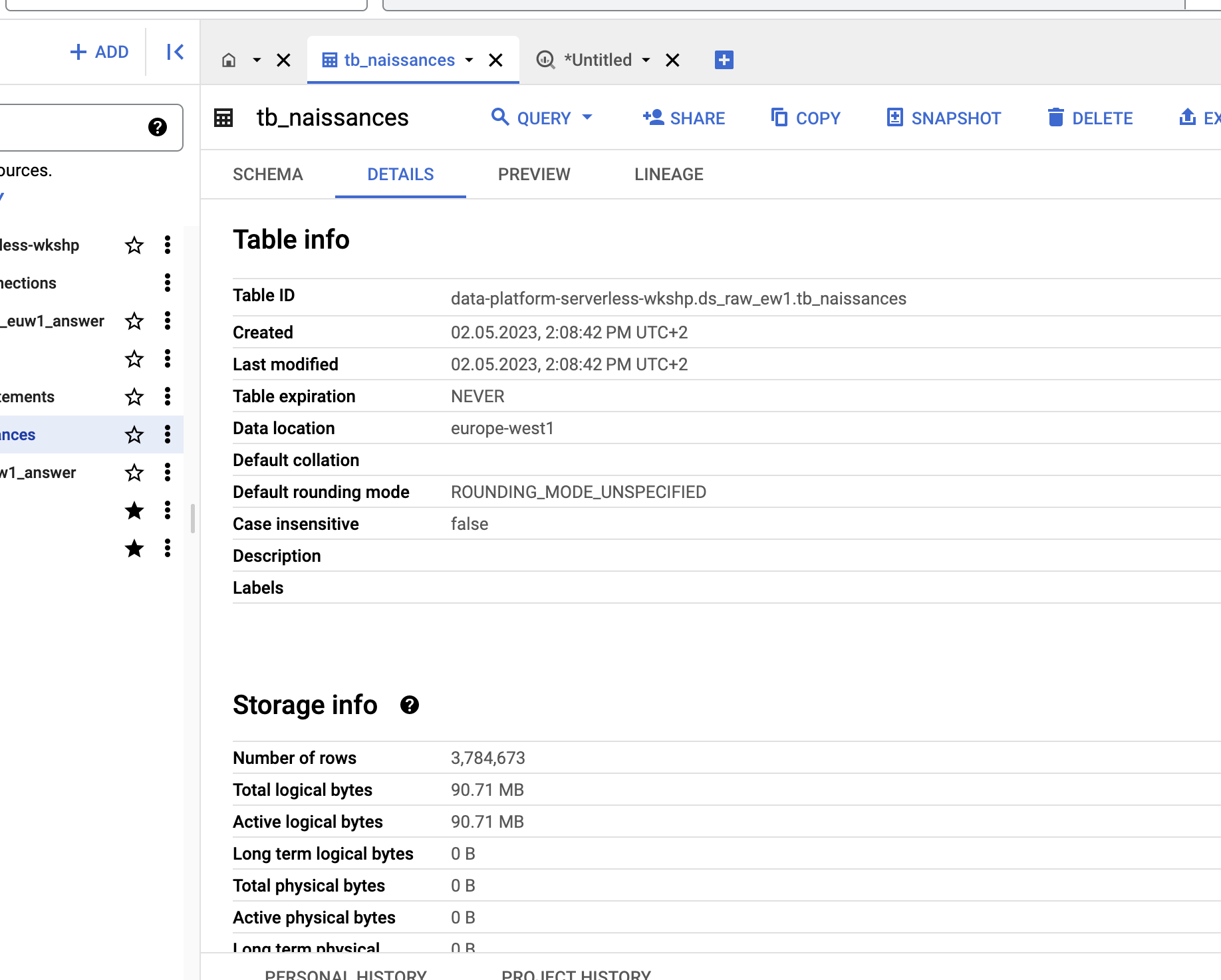
✏ Retournez dans BigQuery : la table tb_naissances a dû réapparaître dans votre dataset ds_raw. Vérifiez qu’elle contient bien 3,784,673 lignes
Si la table n’apparaît pas après avoir déposé le fichier dans le bucket, c’est sans doute qu’il y a eu un problème dans le traitement effectué par la fonction. Pour voir les logs de celle-ci, cliquez sur l’onglet LOGS après avoir sélectionné votre fonction. Attention, les logs peuvent mettre 2 à 3 minutes à apparaître après l’exécution.
|
Désormais, le chargement de nos données est effectué automatiquement dès qu’un fichier de naissances est déposé. Notre couche de chargement des données brutes est terminée, il nous faut maintenant nettoyer et mettre en forme ces données.